What is a Type II Restriction Enzyme?
Script
Type II restriction enzymes are the kind used for most molecular biology applications such as gene cloning, DNA fragmentation, and analysis.
They cleave DNA at fixed positions with respect to their recognition sequences. Over 3,500 Type II enzymes have been characterized, recognizing over 350 different DNA sequences.
Restriction enzymes are named for the micro-organism from which they were originally purified. For example, HindIII was the third enzyme found in Haemophilus influenzae, serotype d.
Type II restriction enzymes vary widely in size, amino acid sequence, domain organization and subunit composition, co-factor requirements, and modes of action.
They are loosely grouped into sub-types based on their enzymatic properties. The four most important subtypes are Type IIP, IIS, IIC, and IIT.
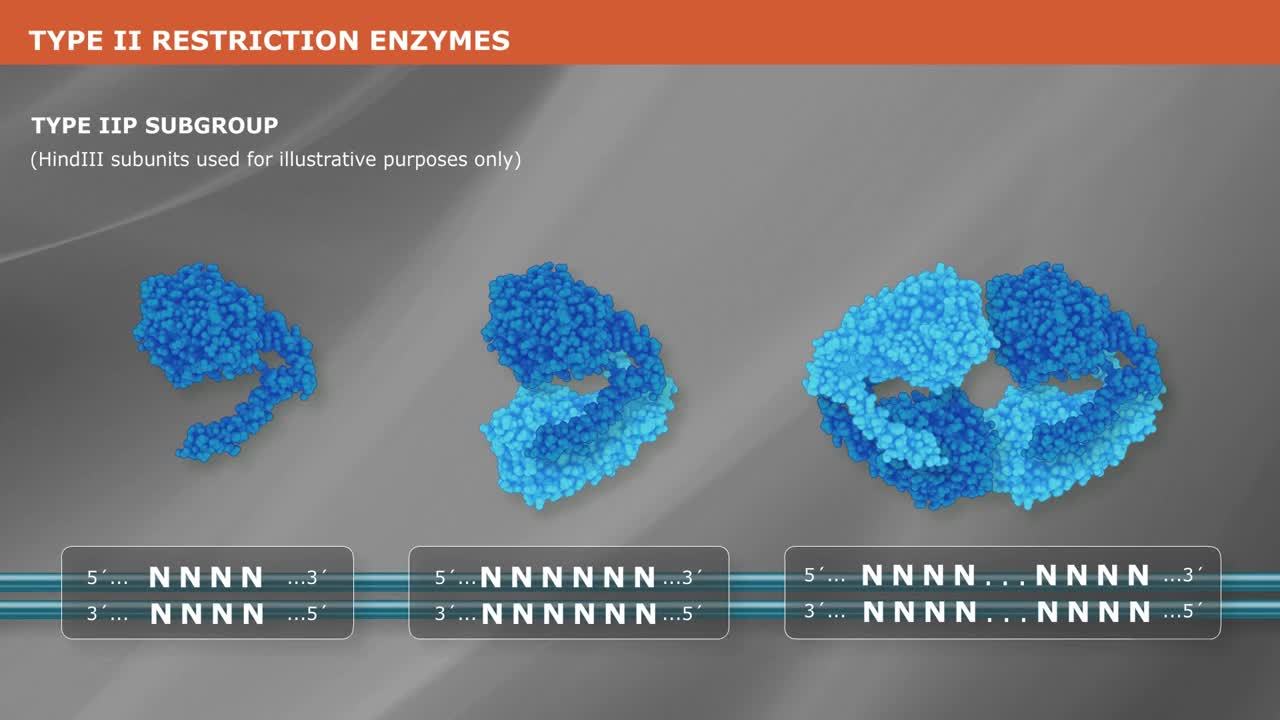
Type IIP enzymes account for over 90% of the enzymes used in molecular biology. They recognize symmetric, or Palindromic, sequences 4-8 base pairs in length, and generally cleave within that sequence. The subunit composition of Type IIP enzymes depends on the length of the enzyme’s recognition sequence.
Enzymes that recognize short, 4-bp, sequences act as monomers, comprising single protein chains, while enzymes that recognize longer, 6-8-bp, sequences typically act as homodimers comprising two identical protein chains. Still other Type IIP enzymes act as dimers of dimers, or homotetramers. These latter bind to and cleave two or more recognition sequences at once.
Upon cleavage, some Type IIP enzymes leave single-stranded overhangs, while others leave blunt ends.
In contrast to Type IIP enzymes, in which the amino acids that catalyze cleavage and those that recognize the DNA are integrated into a single protein domain, in the larger Type IIS enzymes, those amino acids are partitioned into two separate domains, linked by a short polypeptide connector.
Due to this separation, the catalytic domain is positioned to one side of, and several base-pairs away from, the sequence bound by the recognition domain, causing cleavage to be Shifted to one side of the sequence.
Type IIS enzymes generally bind to DNA as monomers and recognize asymmetric sequences, but cleave as dimers.
In Type IIC enzymes, restriction and modification activities are combined into a composite enzyme with three domains: one for cleavage, one for methylation, and a third for sequence recognition. Type IIC enzymes also cleave outside of their recognition sequences.
Type IIT enzymes, in contrast to the previous three subtypes, use two different catalytic sites for cleavage, each of specific for one particular DNA strand. Disruption of either catalytic site results in the creation of a DNA-nicking enzyme that cleaves only one DNA strand.
Related Videos
-

What are Restriction Enzymes? -

What is a Type I Restriction Enzyme? -

What is a Type III Restriction Enzyme?
