Whole Genome Amplification & Multiple Displacement Amplification
Whole Genome Amplification
Whole Genome Amplification (WGA) is a general term denoting methods that aim to amplify an entire genome, typically starting with low (picogram to nanogram) quantities of DNA and producing up to tens of microgram quantities of amplified products. WGA has become an invaluable approach for utilizing limited samples of precious stock material or to enable sequencing of single-cell genomic DNA.
| Reaction Temperature | Amplicon Size | Detection Method(s) |
|---|---|---|
| 30°C | N/A | N/A |
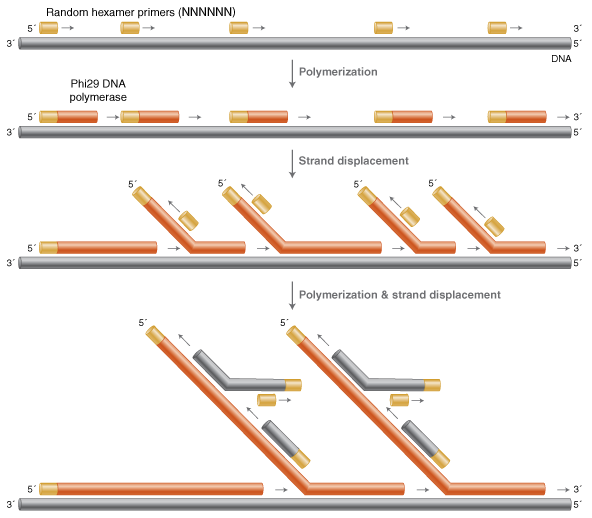
The MDA process begins with random hexamer primers binding to the DNA template. A strand displacing polymerase, commonly phi29 DNA polymerase, initiates amplification with the end result being long, branched networks of DNA. If the DNA products will be used in downstream applications, the branches can be resolved using T7 Endonuclease 1.
Multiple Displacement Amplification
Several methods have been developed for high-fidelity whole genome amplification, including PCR-based methods such as Degenerate Oligonucleotide PCR (DOP-PCR) and Primer Extension Preamplification (PEP), but the most commonly used method is the Multiple Displacement Amplification (MDA) method that uses the strand-displacement activity of DNA polymerases such as phi29 or Bst.
For MDA with phi29 DNA polymerase, random hexamers at high concentration (10–50 μM) are combined with template material and phi29 and incubated for 1–12 hours depending on the level of amplification needed. The proofreading exonuclease activity of phi29 ensures high-fidelity replication of template DNA, but also requires phosphorothioate linkages in the hexamer primers for high efficiency. For high yield reactions, pyrophosphatase can be included to avoid inhibiting the polymerase with the high concentration of pyrophosphate byproduct produced. Products of the reaction are extremely long (>30 kb) and highly branched through the multiple displacement mechanism. For next-generation sequencing applications, acoustic shearing or the NEBNext Fragmentation System can resolve these products into readable fragments as part of the library prep workflow. When using these products for other downstream applications such as nanopore sequencing, the branches can be resolved using T7 Endonuclease 1.
Choose Type:
- Isothermal Amplification Brochure
Brochures
Products and content are covered by one or more patents, trademarks and/or copyrights owned or controlled by New England Biolabs, Inc (NEB). The use of trademark symbols does not necessarily indicate that the name is trademarked in the country where it is being read; it indicates where the content was originally developed. The use of this product may require the buyer to obtain additional third-party intellectual property rights for certain applications. For more information, please email busdev@neb.com.
This product is intended for research purposes only. This product is not intended to be used for therapeutic or diagnostic purposes in humans or animals.

